Cross-Region Disaster Recovery
Mission-critical Nexus Repository deployments are sensitive to cloud platforms' regional outages. A solution resilient to cross-regional disasters maintains availability and data integrity through cross-region replication and failover mechanisms. A record of the data loss during the failover process is preserved to assist recovery.
These deployment instructions are designed and tested for the Amazon Web Services (AWS) environment. Architectures that imitate this environment may be deployed into other environments using their respective technologies, however, they have not been documented or tested by Sonatype at this time.
This solution achieves the following goals:
Recovery Point Objective (RPO) of 15 minutes for the blob stores and 5 minutes for the PostgreSQL database. These numbers are applicable when RDS replication is used.
Recovery Time Objective (RTO) of 1 hour for full-service availability.
Audit list of assets lost during the failover.
Zero-loss fail back to the primary region once an outage is cleared.
Failover When a primary system or location experiences an outage or failure, operations are automatically switched to a secondary or backup system/location. This is called a "failover."
Failover ensures business continuity by allowing critical systems to continue running even when the primary infrastructure is unavailable.
Failback Once the primary system or location has been repaired or restored, "failback" is the process of transferring operations back to the primary system, which is usually the most efficient and optimized environment. Relying on backup systems for extended periods can lead to performance issues and potential vulnerabilities. Failback ensures long-term system reliability.
Failback involves carefully planned steps to ensure a smooth transition and minimize disruptions and no data loss. Network settings need to be updated to redirect traffic back to the primary system. Applications need to be checked to ensure they are functioning correctly after the fallback. Thorough testing is essential to ensure that the primary system is operating as expected and that all systems are working together seamlessly.
Object storage replication Object storage replication involves automatically copying data from one object storage location to another. This process ensures data redundancy, enhances availability, and facilitates disaster recovery. By creating identical copies in separate locations, organizations can protect against data loss and provide faster access to data for users in different geographic regions.
PostgreSQL replica In PostgreSQL, a replica is a copy of a primary database server, designed to provide redundancy and improve performance. It receives and applies changes from the primary server, ensuring data consistency. Replicas can be used for read-only queries, offloading workload from the primary, and disaster recovery, allowing a replica to take over if the primary fails.
Data synchronization Any data changes that occurred on the secondary system during the failover period need to be synchronized with the primary system to avoid data loss or inconsistencies.
The following are failure scenarios are in the context of recovering a Nexus Repository deployed in AWS. Use the Failover Steps below to recover in another region.
Compute Outage A compute outage refers to a situation where the compute service (such as EC2, or EKS) used to run Nexus nodes experiences degradation or is unavailable. Depending on the extent of the outage starting a new node may resolve the issue.
When a complete failure occurs switching to the failover region is required.
RDS Service Outage An RDS (Relational Database Service) outage means that your managed relational database instance, provided by AWS RDS, becomes unavailable.
Recover by switching to a local read replica or failing over to another region.
S3 Outage An S3 (Simple Storage Service) outage signifies that the AWS S3 storage service, used for object storage, is experiencing a disruption. An S3 outage renders artifacts inaccessible, preventing developers from downloading or deploying them.
When implementing cross-region replication the failover region is used for recovery.
Primary Region Outage A primary region outage means that an entire AWS region is experiencing a major disruption, affecting multiple AWS services within that region.
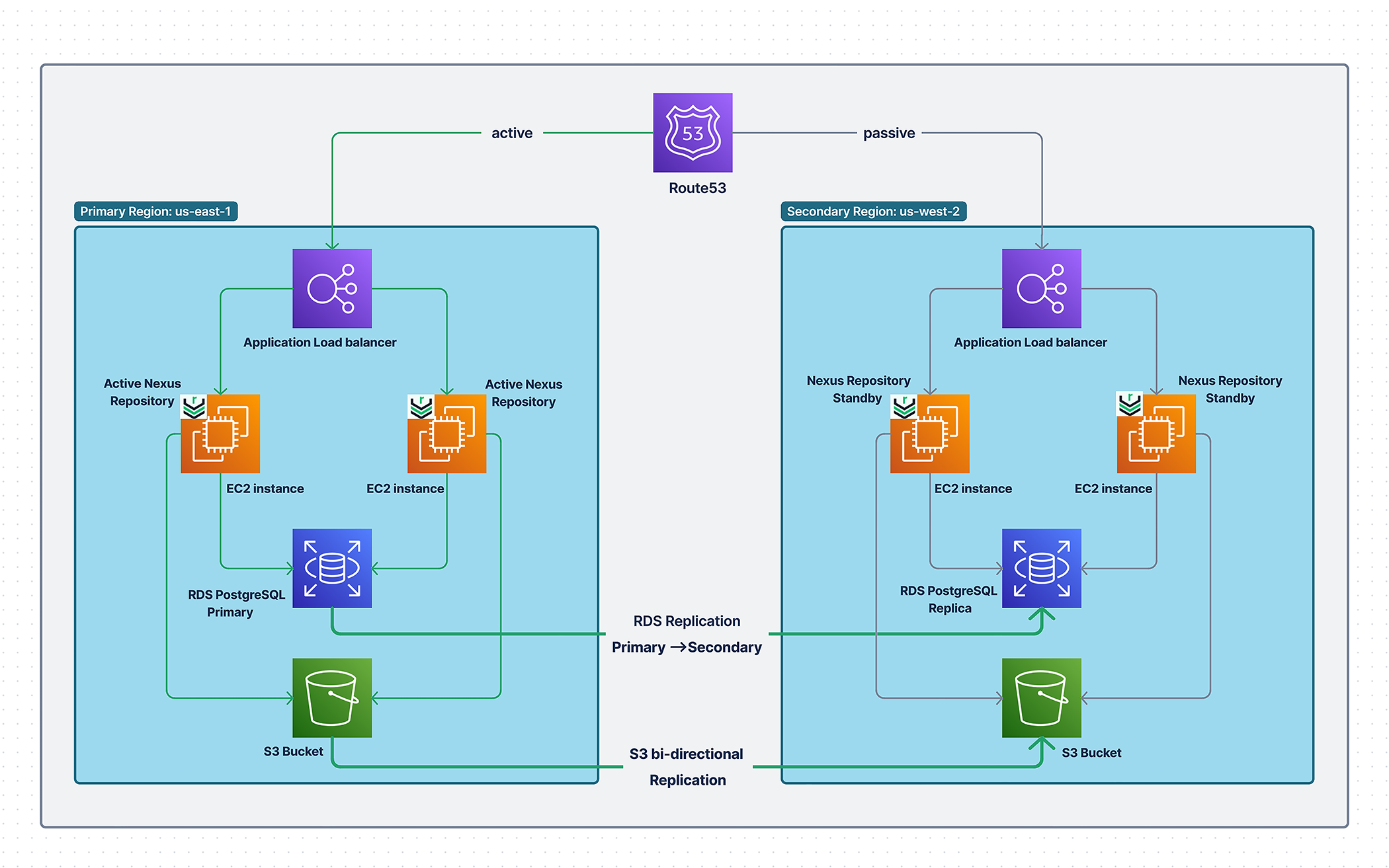
Architectural Overview
Cross-Region Disaster Recovery consists of an active cluster in the primary region with a passive cluster in a secondary region in standby mode. This model uses native cloud services to actively replicate content to the secondary region for the object blob store and the PostgreSQL replica.
Create a Nexus Repository deployment using high availability deployment examples for AWS with an RDS PostgreSQL instance.
Enable versioning for the S3 buckets for replication.
Create an equivalent bucket for each bucket in the failover region with versioning enabled.
Configure bi-directional replication rules for each S3 bucket pair with 'Replication Metrics' and 'Delete marker replication' enabled. Existing objects need to be replicated through S3 batch replication.
Add a read replica in the secondary region to the RDS PostgreSQL cluster.
Update the S3 blob stores in the primary Nexus Repository cluster to specify the failover bucket configurations.
Create an inactive clone of the Nexus Repository deployment in the secondary region. Configure this instance to use the cross-region replica.
Update the Nexus Repository instance in the primary region to be off by default to avoid the service automatically restarting when the region recovers from the outage.
Configure the DNS web service in the hosted zones for load balancing and the database with latency-based routing.
Failover Overview
During regional failure, the cluster in the secondary region is brought online and the DNS directs traffic from the primary region to the secondary region. On initialization of the secondary instance, use the synchronization tasks to validate the data on the instance to ensure consistency of the blob stores and database.
A new blobstore layout is built on initialization based on a date-driven directory structure.
The
Verify and Repair Data Consistencytask configures a reconciliation when selected. The task captures the analysis performed by generating a reconciliation plan. An API endpoint returns the reconciliation plan when executed in dry run mode.The task uses the resolution table to determine the actions to be performed based on the available plans created in dry run mode.
Failover Steps
Use the following steps when designing your recovery runbook:
Monitor database replication until complete.
Stop the PostgreSQL cluster in the primary region when running.
Ensure object store replication is complete by viewing the 'Metrics' tab of S3 to see that nothing is in a 'Pending' state.
Promote the PostgreSQL read replica in the secondary region to a standalone DB instance (primary).
Start the Nexus Repository instances in the secondary region.
Run the synchronization tasks in the secondary region using a timespan before the AWS outage began.
Failback Steps
Create an RDS PostgreSQL read replica in the primary region using the following documentation. The original RDS (standalone) in the primary region may be deleted, as it is redundant at this point.
Monitor RDS replication until within the expected lag window.
Stop the Nexus Repository instances in the secondary region.
Monitor RDS replication until complete.
Stop the RDS PostgreSQL in the secondary region.
Ensure S3 replication is complete using Cloudwatch metrics.
Promote the RDS PostgreSQL replica in the primary region to a standalone DB instance (primary) using the following steps.
See Working with read replicas for Amazon RDS for PostgreSQL
Start the EC2 instances in the primary region.
Create an RDS PostgreSQL read replica in the secondary region using the following documentation. The previous RDS (standalone) in the secondary region can be deleted, as it is redundant at this point.
Synchronization Tasks
Depending on the state of replication for the blob stores and database before the failure, Nexus Repository may be in a state where the database and the blob stores are not consistent with each other. After starting the Nexus Repository on the secondary instance, the Verify and Repair Data Consistency task is used to audit and reconcile differences in the database and the blob stores.
This task is used to target the specific period where the outage occurred and compare the database content with the artifacts found in the blob store.
Differences are cataloged into a recovery plan and then executed with the changes from the plan. Nexus Repository Administrators may review the plan to adjust the scope and prioritize the recovery of critical repositories.
See Tasks
Recovery Tasks After Synchronization
Run the following tasks once the Verify and Repair Data Consistency task is completed. Running these tasks before the restore is complete results in errors for search and browse results.
Repair - Rebuild repository browse Repair - Rebuild repository search # when using npm Repair - Reconcile npm metadata # when using Yum Repair - Rebuild Yum repository metadata (repodata)
Monitoring RDS Replication Completion
Monitoring RDS replication completion involves checking the primarily the instance status and the replication lag.
Check the Instance Status using the AWS Management Console. Navigate to the RDS service in the AWS Console and select "Databases" in the left-hand navigation pane. Replication is generally considered complete when the status changes to available.
Monitor the ReplicaLag until the rate is consistently low or zero. Once the replica status is available, select the replica and navigate to the "Monitoring" tab. The ReplicaLag metric shows how many seconds since the last commit the replica database is behind the source database. A consistently low ReplicaLag value means the replica has processed most or all outstanding changes from the source and is fully caught up. When there is no write activity, the metric increases to 5-minutes at which point a sync occurs resetting the metric to 0 and the sync cycle begins again.
Regional DR Failure Testing
Following the failure response steps results in a working Nexus Repository instance in the secondary region. One thing that we noticed is that the throughput for S3 replication and RDS replication was very high. When simulating the failure over of the primary region almost all the information could be replicated.
Around 45 min was needed to come back to a healthy state without executing the plan.
We recommend setting up bidirectional replication between the primary and secondary S3 buckets. This simplifies failback after recovery.
Nexus takes more time during specific phases in the startup e.g. enabling health checks for each repository and system information generation steps.
It is worth trying to execute the planning phase of the reconciliation task in parallel to reduce the downtime of the instance.
Ensure that delete marker protection is included During the test, we found out that garbage temp blobs were created by Nexus during normal operation because the replication of S3 only copies new files but existing files deleted persist in the failover bucket. As a result of this, we needed to activate the delete marker replication option for the S3 replication rule replicating delete markers between buckets.
PostgreSQL Replication Testing
The following details are taken from the PostgreSQL replication testing.
Copying the before-stated RDS node (110GB total, 88GB Postgres DB) between ca-central-1 and us-west-2 regions takes about 5 minutes.
Taking the replica from a 110GB RDS (~88 GB Postgres) takes between 5 and 10 minutes which is reasonable considering the size, possibly this time can increase linearly regarding the size of the DB/RDS node.