Continuous Monitoring Concepts
Log4j Won't Be The Last
One of the biggest takeaways from the log4j disclosure is that similar events are likely. Vulnerabilities with key structural components will impact organizations everywhere. And vulnerabilities are inevitable, too. Even components stewarded by veteran developers will have flaws.
If you’re a Lifecycle user, then you already have a tool that can protect you from these events. But, if you’re an experienced user, chances are good that your workflow is configured so that applications are being scanned as your CI/CD tools build them. That workflow is extremely effective most of the time, but what happens when an application isn’t frequently scanned because it’s not frequently built? Your organization probably has deployed apps that are widely used but aren’t receiving a lot of development time. Manual scan-and-search approaches after vulnerability disclosures aren’t feasible. Automated approaches help considerably, but are still prone to human error during configuration and setup.
The intersection between sudden vulnerability events and infrequently scanned applications produces an enormous amount of risk. But addressing this risk is possible. Lifecycle has built-in tools that monitor deployed applications and send notifications about new policy violations.
Continuous Monitoring
Continuous Monitoring (CM) is a Lifecycle feature that automatically scans configured applications once a day and sends notifications if new policy violations are discovered. The primary use case of this feature is to monitor deployed applications that are not built regularly. It’s a powerful tool that can keep you informed about your application’s security and health.
Though it’s powerful, Continuous Monitoring is a complex feature with some nuance. Let’s review how it works so that you know what to expect.
Continuous Monitoring must be enabled at both the application and the policy level. Enabling Continuous Monitoring at the application level is how you select applications to monitor, and enabling Continuous Monitoring at the policy level is how you select the policies you want notifications about.
After Continuous Monitoring is enabled at both the application and policy level, you must scan the application through your usual process – the CLI, the browser UI, or through an integration like with your CI/CD tools – to generate a binary fingerprint that acts as a snapshot of your deployed application. Once a day, at a configurable time, the binary fingerprint is checked against Sonatype’s vulnerability and license data and a new set of metadata is created. Lifecycle compares this metadata with your policies, flags any violations, and sends notifications if it detects a change.
Snapshot Used by Continuous Monitoring
Continuous Monitoring evaluates the most recent scan for the application in the stage for which Continuous Monitoring is enabled. Scans performed in other stages are ignored for Continuous Monitoring.
If the application has no scan in the selected stage yet, Continuous Monitoring won’t generate daily evaluations/notifications until at least one scan exists for that stage (this establishes the baseline snapshot).
You can run the establishing scan via the CLI, browser UI, or CI/CD integrations, the latest scan in the configured stage becomes the snapshot Continuous Monitoring checks each day.
Example: If Continuous Monitoring is configured for the release stage, and the most recent scan is in the build stage, Continuous Monitoring still uses the latest release stage scan for its daily checks.
This process has some implications.
Because your application’s binary fingerprint is getting a new set of metadata, Continuous Monitoring can catch sudden vulnerability events like log4j-core.
Like all scans, Continuous Monitoring relies on a good policy set to flag components that need attention. If your policy set is poorly configured, Continuous Monitoring will be of limited value.
Continuous Monitoring will only generate a notification if a new violation is found or a change in the violation’s details is detected. Violations you have already been notified about will not create a new notification.
Because Continuous Monitoring is not associated with a build in your CI/CD tools, reports will not appear in your CI/CD tools. You’ll need to use the browser UI to see the full results of a Continuous Monitoring scan.
When you enable Continuous Monitoring, you will be asked to choose a build stage. Continuous Monitoring always evaluates the latest scan for that application in the stage you select, scans from other stages are not considered by Continuous Monitoring. For best results, pick a stage that isn’t often used for scans to reduce noise in daily monitoring.
Sonatype strongly recommends using Continuous Monitoring. It’s the best way to keep visibility on your deployed applications. Good configuration is necessary for maximum protection. Jump ahead to Further Considerations to learn a little more about what a good Continuous Monitoring configuration looks like.
Notification Options
For Continuous Monitoring, notifications can be configured either through emails or webhooks.
Lifecycle can be configured to send email notifications for events such as new policy violations. This requires you to configure an SMTP server in the Mail Configuration section of the config.yml file. Email notifications from Lifecycle are sent when a policy alert occurs. These emails contain information about the application and violation and include a link to the full results for further investigation. As mentioned, email is a simple and familiar way to get notifications to teammates who need them.
Webhooks
Lifecycle provides webhooks that let you receive notifications about various events — for example when an application evaluation is completed. When these events happen, the Lifecycle creates an object that has relevant information about the event, such as the type and any associated data. Lifecycle then sends that event object to defined URLs using HTTP POST requests. Webhooks are a powerful way to set up custom notifications and integrate with other applications. For example, you can use webhooks for Lifecycle to send Slack messages when a policy evaluation event occurs.
Building Your Monitoring and Notification Plan
Maximizing your protection against vulnerabilities requires a procedural approach to applications that are deployed and in use, but aren’t being regularly built or scanned. That’s a Monitoring and Notification plan.
Developing a Monitoring and Notification plan is a team effort. Start by making a list of key players in your organization who need to be included. That list will likely include DevOps leaders, Application Security leaders, and team members who are knowledgeable about how your organization tracks issues (e.g. Jira), the CI/CD process, and your organization’s existing notification schemas.
Another key set of participants will be product managers. Auditing all your organization’s deployed applications can be a significant undertaking. If your Monitoring and Notification plan isn’t considering every app, it won’t be successful. Product managers will ensure that their apps aren’t missed.
Finally, and most importantly, you must have buy-in from developers. If developers don’t know what to expect from your Monitoring and Notification plan, they won’t be able to respond effectively. No two organizations have identical developer cultures, so work with a dev team leader to find a notification strategy that works and then socialize the plan.
To get the conversation started, review the graphic and table below.
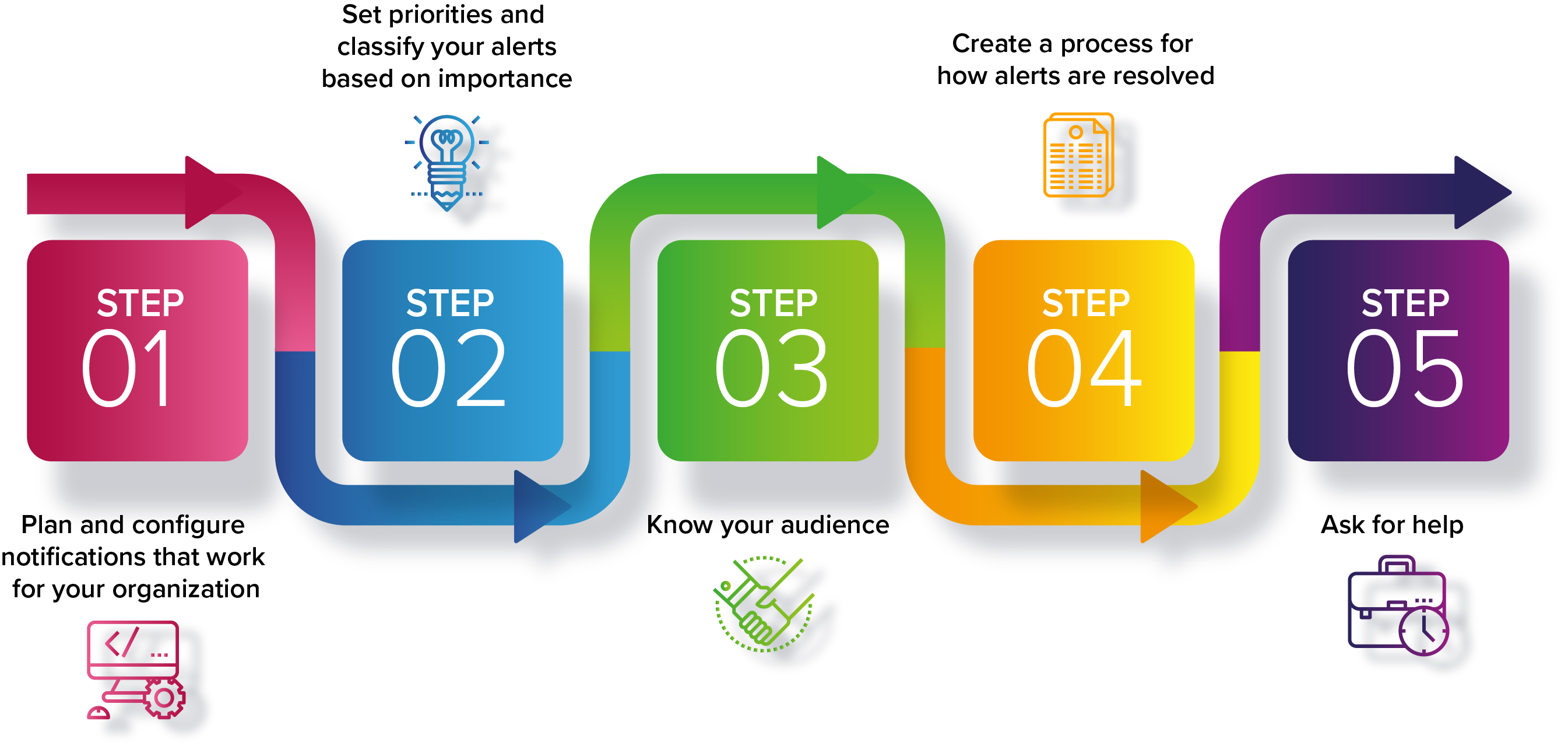 |
Plan and Configure | Review all the monitoring and notification options available to you and decide on a standard for your organization. Configure Lifecycle user roles. Identify stakeholders and determine how teammates/stakeholders will be added or removed from notification lists. Consider other monitoring and notification strategies that are in place in your organization. |
|---|---|
Set Priorities | Not all applications are equally critical. Your most important applications can have notifications enabled for more individuals and in more places. Less-important applications can have fewer notifications sent to just key stakeholders. |
Know Your Audience | Configure notifications so that developers are only notified about the applications they own. Socialize your intentions so that stakeholders know what to expect. Reduce noise by enabling notifications only where they’ll be seen. Determine where your developers look first – Slack? Jira? Email? |
Create a Process | Outline a process for handling notifications. Who’s responsible for remediation, or for requesting waivers? How can those individuals prove that the situation is resolved, and who should they report to? And notifications aren’t useful if you don’t know how to address the risk. If you haven’t considered how bad components should be remediated, now is the time to develop a workflow. |
Ask for Help | Sonatype has resources to help you make these important decisions. Take advantage of the Sonatype Community and all the resources at my.sonatype.com |
Further Considerations
Set criteria for deciding which apps should be monitored. Think about the number of users you expect, whether the application is internal or external, hosted or distributed. Some applications are resistant to some possible exploits, and some applications won’t need maintenance.
Set criteria for when an application should enter and exit Continuous Monitoring. Some factors might be the application’s strategic role in your organization’s goals, the number of users, and the overall development budget.
Notifications can be configured to send to specific email addresses, or to all users with certain roles inside IQ Server. An audit of users, roles, and permissions will ensure that notifications go to the right people.