SCM Features Technical Overview
Overview
Most of what IQ for SCM does is behind the scenes and the outcomes of it generally manifest themselves in the source control management system rather than in IQ Server itself. As such, it can be difficult for users to know exactly what IQ Server is actually doing on their behalf with respect to IQ for SCM features, when, and why.
The purpose of this document is to explain what many of those "behind the scenes" things are, how they work, why they work the way they do, and to provide some level of technical detail.
How IQ Server interacts with SCM systems
There are two primary ways in which IQ Server interacts with Git-based SCM systems:
via the SCM systems' web-based REST APIs
All of the various SCM systems IQ Server interacts with provide an API for doing various things like creating pull requests, commenting on pull requests, creating commit status, etc.
To protect their systems against abuse and ensure availability each SCM system imposes some sort of API 'rate limiting'. This is discussed in more detail later in this document.
via a Git client
IQ Server uses Git itself for things like checking for new commits or pulling down manifest files for analysis.
There are two Git clients that IQ Server can use:
native Git client
the native git client is installed as a separate tool on the machine where IQ Server is running
this is the preferred client since it allows IQ Server to do shallow clones and sparse checkouts which means IQ Server only pulls down the files necessary for component analysis
Java Git client
considered a backup in case a native git client is not installed
IQ Server has to clone the entire repository when using this client
For more information see Source Control Git Client Configuration
How IQ Server doesn't interact with SCM systems
IQ Server does not currently support direct SCM to IQ Server communication (i.e. webhooks).
Here's what happens when a policy evaluation occurs
The following diagram illustrates the various SCM operations IQ Server can perform behind the scenes in response to a policy evaluation.
|
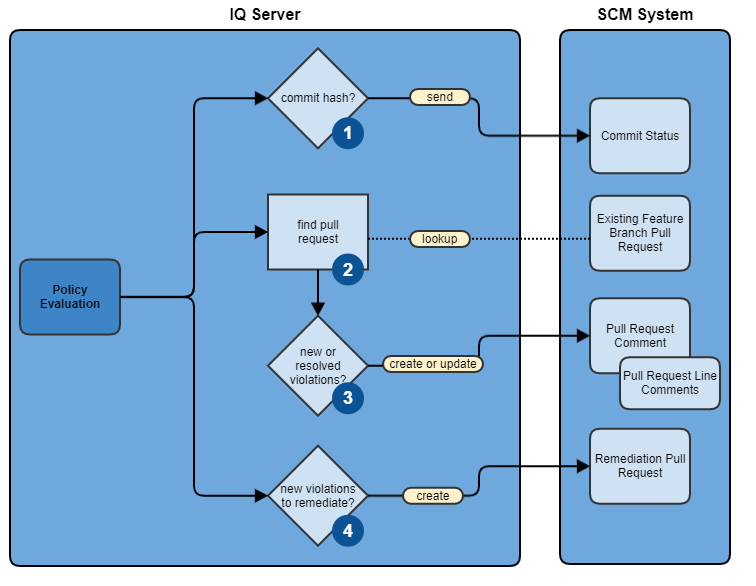
It is assumed at this point that the IQ application is properly associated with an SCM repository via the application's source control configuration.
If there is a commit hash associated with the policy evaluation, then the commit status is sent to the SCM system.
The commit hash is typically added to the policy evaluation request by either the CLI or CI tooling
If the commit is for a feature branch try to find one or more pull requests associated with it.
Create or update a pull request comment if there is a pull request and the following conditions are met:
Pull request commenting is enabled for that IQ application
Policy evaluation reports exist for both the feature branch of the pull request and the branch the pull request is targeting (usually the default branch)
There is a notable difference in the two reports (i.e. some new policy violations appeared or some existing policy violations were resolved)
Optionally, line comments will also be created if IQ Server can identify the source code location(s) for introduced violations
Create a remediation pull request if all of the following conditions are met:
Automated remediation pull requests are enabled for the IQ application
The policy evaluation is for the configured default branch
There are one or more components with policy violations
A component either hasn't had a remediation PR created for it yet or there is a new remediation for it
IQ Server can find the location in the source code to apply the remediation
Automated Remediation Pull Requests
Remediation pull requests can be created automatically by IQ Server when a policy violation is detected for a component AND there is remediation available that will correct the violation.
The following diagram illustrates the various ways that the creation of an automated remediation pull request can be triggered.
|
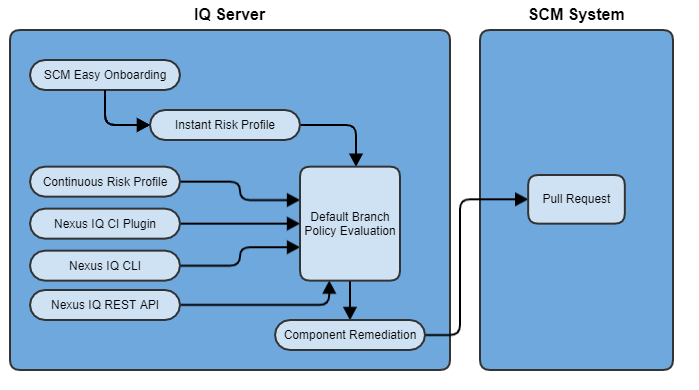
Instant Risk Profile
When the customer uses Easy Onboarding to add new applications/repositories to IQ Server an initial source control evaluation is performed against the contents of the given repository(s). This evaluation is performed at the 'source' stage.
Continuous Risk Profile
IQ Server monitors the default branch of each repository daily and if a new commit is detected (once per day) IQ Server will perform a source control evaluation, again at the 'source' stage. This keeps the 'source' stage report on the Reports page in IQ Server relatively up to date.
Nexus IQ CI Plugin
Any of the various CI plugins (i.e. Jenkins, Bamboo, GitLab pipeline, etc.) can be used to initiate a policy evaluation. The customer can configure the plugin to use whatever stage they prefer, but here are some recommendations:
all feature branch policy evaluations should be done at the 'develop' stage. These evaluations represent disparate point-in-time snapshots and thus report history is not maintained nor desired, which is the intent of the develop stage.
for evaluations of the default branch repository contents (i.e. source code) it is recommended to use the 'source' stage
for evaluations of build artifacts it's recommended to use the 'build' stage for CI type processes and the 'stage' and 'release' stages for the release process.
Nexus IQ CLI
A customer can use the CLI tooling to manually initiate a policy evaluation and even possibly incorporate these tools into their custom automation processes. The stage recommendations noted above apply here the same.
Nexus IQ REST API
The IQ REST API can also be used to initiate a source control evaluation against the contents of the repository. This would typically be done via some automation process/tooling. The recommendations here would be to use the 'develop' stage for feature branch evaluations and the 'source' stage for the default branch evaluations.
Special note on scan targets
The various tools mentioned above that users have direct control over (CI plugins, CLI tooling, REST API) allow the user to specify scan targets. This allows customers to setup different IQ Server applications for different parts of their repository, whether those be separate modules or folders, etc. For example, let's say that a given repository represents a customer's business application. There could be multiple teams contributing to that application, each responsible for a different aspect of it (i.e. frontend/UI, B2B integrations, services, data, etc.). The user could create an IQ Server application for each one of those aspects and, using scan targets, associate a different part of the repository with each of the corresponding IQ applications.
Scan targets are not currently available directly in IQ Server via Instant Risk Profile nor Continuous Risk Profile. In those cases the entire contents of a given repository are evaluated.
Pull Request Commenting
Pull request commenting is more complex than what was described earlier as there are other flows, in addition to policy evaluations, that can trigger IQ Server to create or update pull request comments. Those flows will be described below.
First, it's important to point out a few things about PR commenting:
The intent of IQ Server PR comments is to inform developers when a new policy violation is introduced with the work they are doing on their feature branch or to pat them on the back when they resolve a policy violation.
IQ Server doesn't compare internally triggered evaluations of static source code with CI triggered evaluations of build artifacts. The potential for confusing results is too high in this case.
Pull request commenting is based on the difference between two policy evaluation reports. The diagram below illustrates the process of selecting the commits used to look up the evaluation reports. Note, this is a more complicated example depicting a branch on branch scenario, but it allows the full selection process to be explained. Most times pull requests will be for a feature branch directly off the default branch.
|
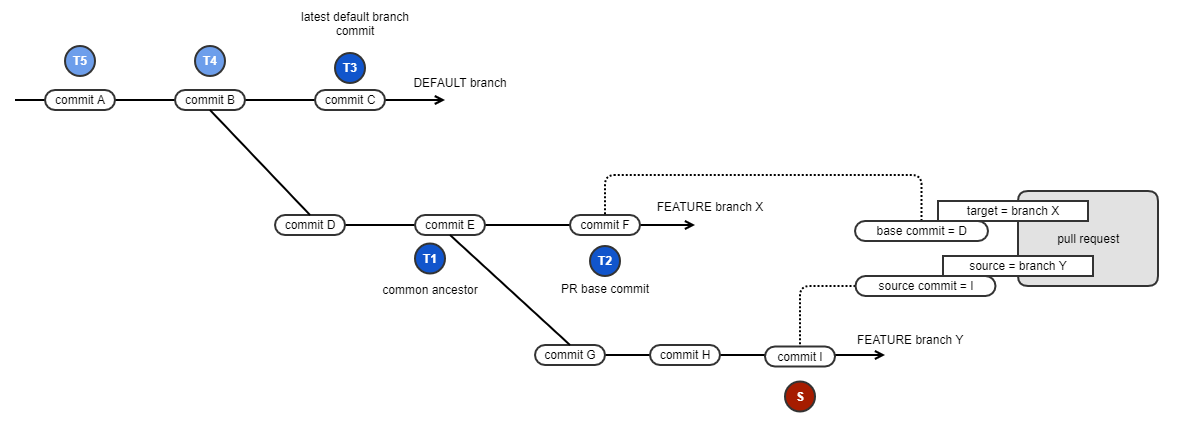
First, the pull request as defined in the SCM system is based on these two branches/commits:
The developer made their changes on feature branch 'Y' with the latest commit being commit 'I'
The developer wants to merge their changes into feature branch 'X'
So, the source commit (S) of the PR is the head commit of the feature branch, in this case commit 'I'. The policy evaluation associated with this commit will be compared against the target evaluation selected next.
Selection of the target commit follows this progression:
T1 : the common ancestor between the two branches is preferred if there is a policy evaluation associated with it
T2 : the base commit specified in the PR itself. The reason the base commit is not the preferred commit is that there could be newer changes to the target branch (from other merged PRs, for example) which might not accurately reflect what the developer currently has on their feature branch Y. If the source branch is kept in sync with the target branch then T1 and T2 would be the same.
T3, T4, T5, etc. : finally, the commit history of the default branch is considered and the first one that has an associated policy evaluation is used
Special note about source control evaluations: If IQ Server is performing the evaluations (i.e. in those cases where CI or other automation processes are not) then IQ Server will always use 'S' and 'T1' as IQ Server will perform those associated evaluations if they don't already exist.
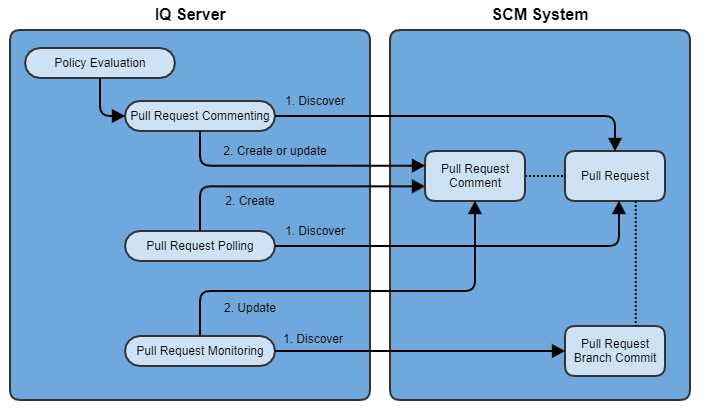
Pull request commenting flows
There are several ways that pull request comments can be triggered:
In direct response to a policy evaluation, as was described earlier
Via a polling mechanism for those cases where a pull request is created after the policy evaluation occurs
When a new commit is detected on the pull request feature branch (pull request monitoring)
|
Polling SCM for new pull requests
Looking for pull requests to comment on in response to a policy evaluation works fine, but what if the pull request is created AFTER the policy evaluation occurs (which is very likely in many scenarios)?
In this case IQ Server needs some mechanism to discover new pull requests. It's already been mentioned that IQ Server doesn't currently accept notifications from the SCM system itself so this is where polling comes in - IQ Server periodically asks the SCM system if there are any new pull requests.
GitHub allows API requests to fetch pull requests across all repositories the configured token user has access to. This means, for GitHub, that IQ Server needs to make far fewer requests and can get back more data in each request, which is good.
For the other SCM systems IQ Server has to contact the SCM system for each repository one by one, which results in far more requests to the SCM system, which is not ideal.
In either case, IQ Server has to periodically cycle through all the configured applications/repositories while trying to balance (a) the desire to comment on a pull request soon after it's created with (b) the requirement to not exceed SCM API rate limits. So, for organizations with a lot of applications and repositories it can take a considerable amount of time to cycle through all of them and the HTTP traffic to the SCM system could be steady and continuous - as one cycle ends a new one would begin. To give some context, as an example it could take upwards of 20 minutes or so to complete one cycle through 1000 repositories.
Note: If pull request commenting is disabled for a given IQ application that application will not participate in pull request polling. So, if there are repositories that are inactive and/or you don't care about receiving pull request comments it's recommended to disable this feature.
Monitoring pull requests for new commits
Once a pull request is created and IQ Server discovers it, what if there are new commits to the pull request?
First, if CI is setup for the associated repository to run a policy evaluation sometime during the build pipeline this will trigger a policy evaluation, which will trigger a new/updated PR comment, as needed.
To account for those cases where CI is not setup to do this IQ Server regularly checks for new commits to existing PR feature branches an uses the Git client itself, rather than the SCM sytem's API.
CI driven vs. IQ Server driven PR commenting
IQ Server supports two approaches to PR commenting:
The preferred approach is to base comments on customer initiated policy evaluations via their CI systems or other automation processes. This allows the customer to specify exactly what they want evaluated, including build artifacts, and when.
In those cases where the customer hasn't setup CI/automation yet on a given repository IQ Server will still detect pull requests, and noticing that these CI initiated policy evaluations are not occurring, will initate evaluations on the contents of the repository to produce the necessary policy evaluations to base the comments on.
The following diagram illustrates this in more detail (please note the use of IQ Server stages):
|
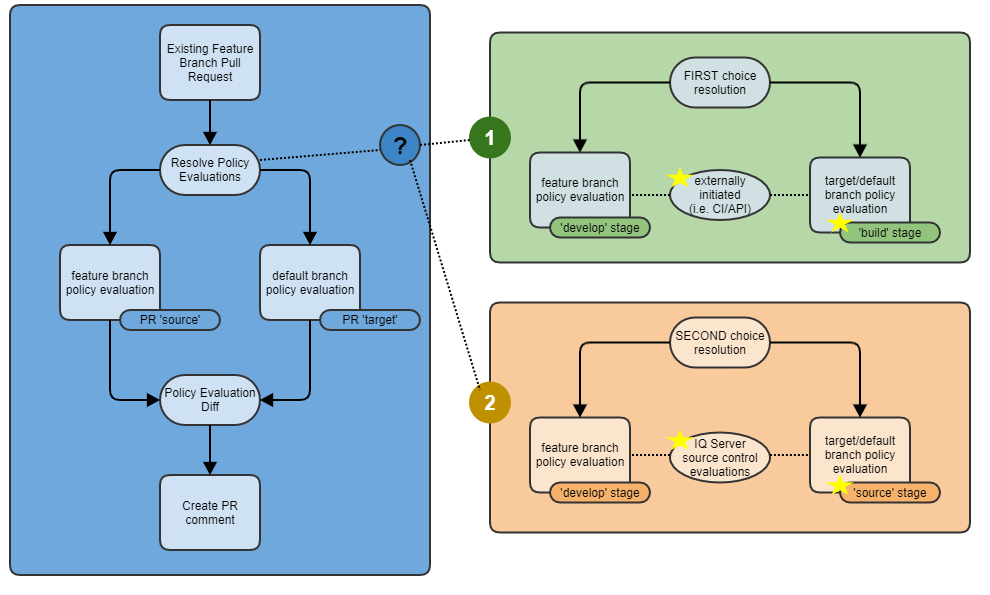
External/CI/API initiated policy evaluations are preferred for a few reasons:
the customer directly controls this
most likely evaluating artifacts that are produced by a build process, which might more accurately depict the contents (from a component/dependency perspective) of the application
more fine grained control of what gets scanned and evaluated via 'scan targets'
control over when and how often the evaluations occur
Secondarily, in the absence of external policy evaluations IQ Server will initiate and perform evaluations on the contents of the source control repository
provides a bridge between initial onboarding and the establishment of CI or other automation processes
no fine grained control of what gets scanned and evaluated - the entire contents of the repository are considered
no control over when or how often evaluations occur - they happen as needed
Dealing with SCM API rate limits
All of the source control management systems enforce some form of limitation on the volume and frequency of interaction with their APIs, with GitHub being the most restrictive in our experience. For example, GitHub restricts API requests to no more than 5000 per hour for a given user and specifies at least a one second delay between requests.
Note: On premise installations, such as GitHub Enterprise, typically give users control over setting API rate limits or disabling them completely. IQ Server does not currently have a way to know this and therefore has been designed to work within the confines of the default published rate limits.
Obviously, as the number of applications/repositories being managed by IQ Server increases the load on the SCM API also increases.
Let's look at the effect of a policy evaluation on the API load. In response to a policy evaluation the following API interactions may occur:
API call to send commit status
API call to discover pull requests
Possibly one or more API calls to delete existing line comments for a PR
Possibly one or more API calls to create line comments
API call to create a pull request comment
This is in addition to the steady load on the API that PR polling introduces.
IQ Server deals with these API rate limit restrictions in a few ways:
Work that requires interaction with the SCM API is put into a queue (effectively one queue per configured SCM user/token)
Each queue is processed in an orderly and controlled manner so as not to overwhelm the SCM system
Algorithms to monitor and fine-tune the pace of requests
What is the effect of all this?
Well, as the number of IQ applications/SCM repositories increases so does the workload. But since the work has to be processed at a steady, consistent pace it can take seconds, minutes or tens of minutes before a comment is added to a pull request, for example.
What can organizations do?
Since the SCM system API limitations are per user, for organizations with hundreds or thousands of repositories it's recommended to create multiple users/tokens and use different tokens for different sub-organizations in IQ Server. This effectively lets IQ Server perform more work in parallel with the SCM system. Note, these additional tokens must be for distinct SCM users - multiple tokens for the same user will not help since the API rate limits apply at the user level, not the token level. Consider one user/token for every 500 repositories as a reasonable starting point.
Note: Pull request comments and automated remediation pull requests, in the SCM system, will appear to come from the user associated with the token configured for the corresponding application in IQ Server.