Scaling with Proxy Nodes
Operating a mission-critical Nexus Repository deployment may mean serving a significant read load. In these cases, we recommend directing read-only traffic to a proxy node and offloading requests from the primary server. This topic covers a common scalability pattern that relies on proxy repositories.
Use Cases
This reference architecture is designed to do the following:
Improve scalability when a large read load is too much for your primary Nexus Repository instance
Improve availability in response to large spikes in read requests
Requirements
To implement this reference architecture, you will need the following:
The latest version of Nexus Repository
Load Balancer when managing more than a single proxy node (e.g., nginx, AWS ELB, etc.)
Separate storage for each node
Setting up the Architecture
This architecture contains the following elements:
A Nexus Repository primary node: the system of record for components in hosted repositories
One or more Nexus Repository proxy nodes
A load balancer to distribute the read traffic among the proxy nodes
Note
The read-only traffic must use a different URL than the primary node. This traffic is not separated using the load balancer.
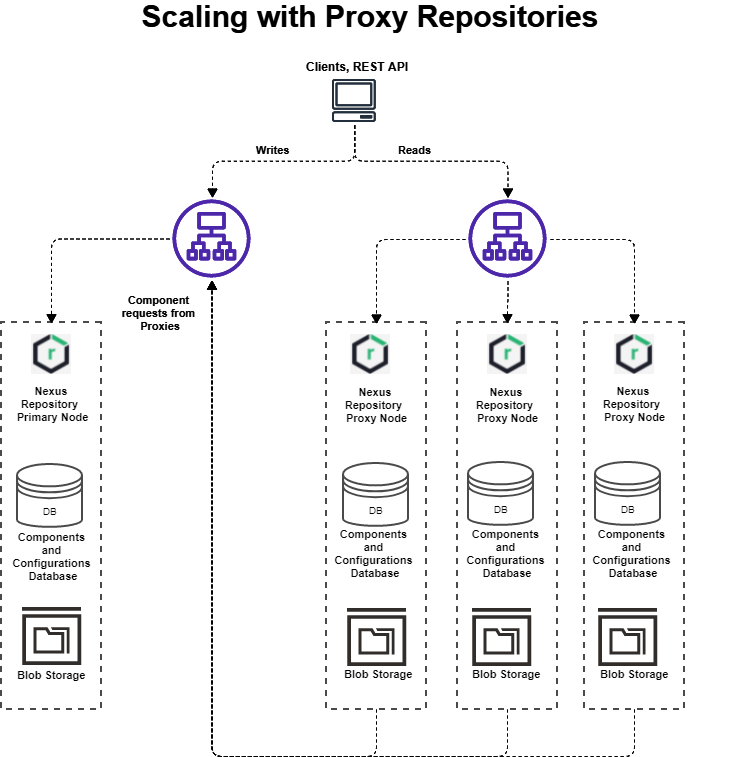 |
The Primary Node
This document assumes that the primary node is pre-existing and that only the layer of proxy nodes is new.
The primary node may itself be a more complex deployment with a load balancer, such as one of the resilient deployment models, or a legacy High-Availability Clustering (HA-C) cluster.
Configuring the Proxy Nodes
Proxy Nodes Location
In this reference architecture, the proxy nodes are deployed in the same data center or availability zone (AZ) as the primary node to keep the request latency low.
In the case of cloud deployments that have a resilient primary node (a deployment that spans multiple cloud AZs), the proxy nodes should also be spread between multiple AZs. This ensures that proxy nodes with warm caches are still accessible should an AZ fail.
All repositories in the primary node must exist in the proxy nodes in both AZs.
Proxy Nodes are Independent
Other than proxy connections, each proxy node is independent of its peers and the primary node. They must not share blob storage, application folders, or external database instances (if applicable), nor should they be part of an HA-C cluster.
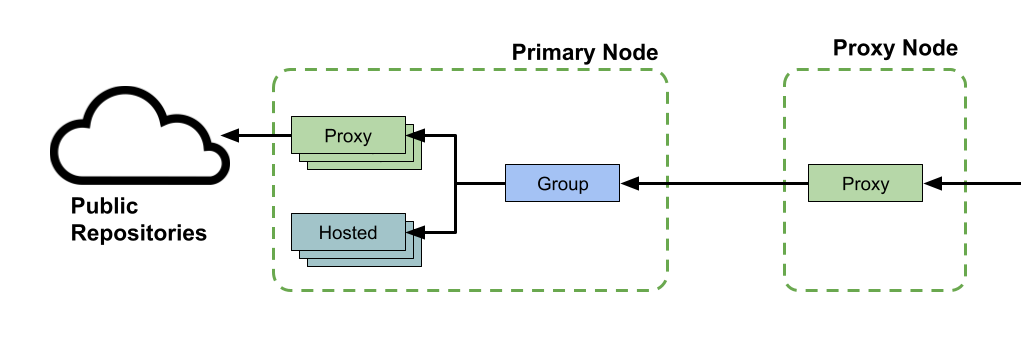
Repositories on the Proxy Nodes
The proxy nodes should have a proxy repository configured for each end user-accessible repository on the primary node.
The set of repositories on the proxy nodes does not need to exactly match the primary node. While the primary node will often have several hosted and proxy repositories, these may not all be directly accessible to downstream consumers. Instead, they should be aggregated behind group repositories for ease of use. When this is the case, the proxy node only needs to define a proxy repository for each group on the primary.
 |
Proxy Cache Settings
Proxy repositories have negative cache settings that control how frequently they re-check for unavailable components. You should leave these set to their default values on the proxy nodes.
If you frequently publish new versions of components, reduce the setting for maximum metadata age from the defaults or set it to zero to ensure that the proxy node regularly checks the primary node.
Third-Party Components
For this reference architecture, we recommend that you proxy third-party components through the primary node. This is key to ensure that the primary node is a cache of records for third-party dependencies, which allows repeatable builds.
This also centralizes any repository routing rules at the primary node, reducing the amount of configuration that you must maintain at each proxy node.
Cleanup Policies
Because the proxy nodes are not the system of record for any components, you can configure aggressive cleanup policies for them. As a baseline, we suggest removing all components that haven’t been downloaded in only a few weeks.
Load Balancer
This reference architecture is compatible with a broad range of load balancers such as the following:
AWS ELB
Nginx
One simple balancing strategy is "round robin," and this is adequate for most deployments; for other options, see Advanced Considerations.
Setting up a load balancer requires header changes similar to those required by a reverse proxy. See Run Behind a Reverse Proxy for examples.
Considerations and Limitations
Choosing the Number of Proxy Nodes
The number of proxy nodes you will need depends on your use case. To improve the scalability of a primary node under continuous read load, a single proxy node may be sufficient.
For situations with large request spikes, it may be necessary to use multiple proxy nodes with repository-replicated caches to protect the primary.
Authentication
If the read load is anonymous (unauthenticated), then no special handling is required. However, if the read load is authenticated, then you should use an external identity provider (LDAP, SAML) so that credentials are synchronized for each user.
For authenticated read loads, you will need to set up the appropriate roles, privileges, and content selectors on each proxy node.
User Token Authentication
We do not recommend using this pattern with user tokens as they are not synchronized between the various instances.
Maven Repositories and Search Results
Using this pattern may reduce search result completeness for Maven users as they must rely on Nexus Repository’s built-in search features (the UI or REST endpoints).
Nexus Repository’s built-in search only shows results for components that have been cached on that proxy node; it will not show components that are available on the primary and not yet cached on a proxy node.
This limitation does not apply to the search commands of non-Maven clients using Visual Studio’s NuGet functionality or the npm command-line client. Nexus Repository passes these ecosystem-specific search commands upstream from the proxy node to the primary node and from primary to remote repositories (if applicable).
Changes to Primary Node Repositories
From time to time, you may add or remove repositories from your primary node. This will require keeping the proxy nodes updated with appropriate configurations.
For proxy nodes that are long-lasting, the simplest approach is to use the Repositories REST API to add, update, and remove repositories from the proxy nodes as necessary.
Advanced Considerations
Node Sizing and Configuration
When considering this pattern, the primary node should already be an enterprise-sized machine capable of coping with your regular loads. For this pattern, the number of Jetty Threads can be increased from 400 (default) to 600.
An example primary node configuration could appear as follows:
CPU: 16 Cores
RAM: 64GB
Memory Configuration: -Xms6G -Xmx6G -XX:MaxDirectMemorySize=15530M
Jetty Thread Configuration: 600
A proxy node machine could look like this:
CPU: 16 Cores
RAM: 32GB
Memory Configuration: -Xms6G -Xmx6G -XX:MaxDirectMemorySize=15530M
Jetty Thread Configuration: 400
Proxy Repositories - Metadata Maximum Age: 0
Cleanup Policy:Aggressive, see Cleanup Policy section above.
Do not modify negative cache settings from their defaults for this use case.
Proxy Node Storage Size
The optimal storage size for each proxy node will depend on the characteristics of your load (e.g., if there is diversity or commonality in the components most requested by the readers) and the rate of new component production.
Whatever size you choose, use a cleanup policy that will keep the overall storage level within the allocated storage.
Multiple Proxy Node Sets
If the primary node has a large number of repositories, you may want to split them among separate sets of proxy nodes to improve the chance of a cache hit. Each pool only covers a subset of the repositories in the primary node.
In this model, the load balancer must decode the HTTP request and route the traffic to the appropriate proxy node pool.
Proxy Node Cloning
In the recommended model, any new proxy nodes added to the pool will start with empty caches; cache misses will be common until the proxy node has time to catch up. Initially, this may detract from the overall performance of downstream clients. If the primary node has a lot of components (i.e., hundreds of thousands or millions), it may take some time before the cache is sufficiently warm to improve performance overall.
One technique for reducing the cache warming time is to clone an existing proxy node. You can do this using a normal backup and restore process on a proxy node, or by creating a snapshot at the VM or storage level and using it to instantiate a new proxy node.
Cloned nodes will start with a warm cache. Depending on the nature of the workload, even a clone from a days-old backup can be a significant improvement over an empty cache.
If you are using a cloud blob store (e.g., S3, Azure, etc.), the Nexus database includes a reference to a specific storage bucket. If you clone the Nexus Repository database/instance, this can cause two Nexus Repository instances to attempt to use the same bucket for blob storage, which will cause issues. Instead, you will need to create a different bucket and change the blob store configuration using the NEXUS_BLOB_STORE_OVERRIDE environment variable to use the new bucket as described in Using Replicated S3 Blob Stores for Recovery or Testing.
Proxy Node Cache Metrics
Cache hit and miss rates can be calculated from the data available at the Nexus Repository metrics endpoint ./service/metrics/data. Calculating the inbound vs. outbound requests through the proxy node.